




Databases
Postgres Performance: Multi-Row Insert
30 Jan 2023
Most people who have experience with relational databases such as SQL Server, Postgres, and MySQL will be aware of the benefits of using bulk insert techniques to write data to the database instead of iteratively writing data as lots of individual statements. In this post I will compare the performance of a multi-row insert, a common way of bulk inserting data, in Postgres with a simple iterative insert which sends one SQL statement per row.
A multi-row insert is a database feature which allows you to insert multiple rows into a table with a single
SQL statement. It can be done by supplying multiple sets of values, each representing a row to be inserted
into the table, to the VALUES clause of the INSERT command. This way we can build up a single SQL statement
for many rows and send it altogether to the database to be executed.
As an aside, Postgres also supports a COPY command which is great for loading large volumes of data. It copies data to and from files but I'm not going to cover it in this post.
This post should highlight the importance of using bulk inserts and what may be surprising, even if you are familiar with bulk inserts, is just how much better a multi-row insert can be even when dealing with a small number of records.
A Quick SQL Example
Before I get into the performance comparison, let's look at some example SQL of the two approaches. These examples will use the schema below. It is deliberately simple with no indexes or foreign key references which might affect the write performance when inserting into the table.
CREATE TABLE person
(
id BIGSERIAL PRIMARY KEY,
first_name TEXT NOT NULL,
last_name TEXT NOT NULL
);This first query is representative of what a simple approach to inserting multiple records may look like:
INSERT INTO person (first_name, last_name)
VALUES ('Jason', 'Mitchell');
INSERT INTO person (first_name, last_name)
VALUES ('John', 'Smith');
INSERT INTO person (first_name, last_name)
VALUES ('Jane', 'Doe');For the three rows we want to insert, we have three distinct INSERT statements. This second query is
an example of the equivalent multi-row insert:
INSERT INTO person (first_name, last_name)
VALUES ('Jason', 'Mitchell'),
('John', 'Smith'),
('Jane', 'Doe');Here we insert three rows into the person table with one INSERT statement by comma-separating the values.
This query will be executed as a single command against the database. When using this approach it is
important to split the data into batches to avoid problems like excessive memory usage or long-running
transactions. For example if we were inserting 2000 records in batches of 1000 we would create two INSERT
commands:
INSERT INTO person (first_name, last_name)
VALUES ('Jason', 'Mitchell'), -- row 1
('John', 'Smith'), -- row 2
... -- row 3 - 999
('Jane', 'Doe'); -- row 1000
INSERT INTO person (first_name, last_name)
VALUES ('Joe', 'Bloggs'), -- row 1001
('Jane', 'Smith'), -- row 1002
... -- row 1003 - 1999
('John', 'Doe'); -- row 2000The optimal batch size will depend on things like the amount of memory available, the size of the data, being inserted, and the number of columns in the table. For a specific use case it is important to experiment with different batch sizes and monitor the performance to determine the best batch size. I tend to start with a batch size of 1000 and adjust from there. Ultimately, the best batch size is the one that strikes a balance between inserting data quickly and efficiently, and avoiding performance issues such as out-of-memory errors.
Performance Comparison
Full disclaimer: my approach to comparing the two approaches isn't particularly scientific but it should make clear the performance benefits of using a proper approach for bulk insert. To summarise the testing process:
- The
persontable from the sample above was used as the target of theINSERT - Queries were executed against Postgres running in Docker (which had 3 CPUs and 7gb RAM allocated)
- Queries were executed within a transaction
- Multi-row queries were executed in batches of 1000
- 3 samples were taken for each batch size and the average used as the result
- Queries were executed from a C# application and the execution time was recorded using the
Stopwatchclass in .NET - The table was truncated between each test
Here is the table of results:
| Batch Size | Simple Insert Execution Time (ms) | Multi-Row Insert Execution Time (ms) | Improvement |
|---|---|---|---|
| 1 | 4 | 3 | 33% |
| 10 | 15 | 4 | 275% |
| 50 | 68 | 3 | 2167% |
| 100 | 133 | 4 | 3225% |
| 250 | 306 | 6 | 5000% |
| 500 | 606 | 8 | 7475% |
| 1000 | 1358 | 11 | 12,245% |
| 2500 | 3527 | 28 | 12,496% |
| 5000 | 6587 | 56 | 11,663% |
| 10,000 | 11,448 | 95 | 11,951% |
| 25,000 | 29,155 | 225 | 12,858% |
| 50,000 | 58,897 | 481 | 12,145% |
| 100,000 | 120,394 | 1017 | 11,738% |
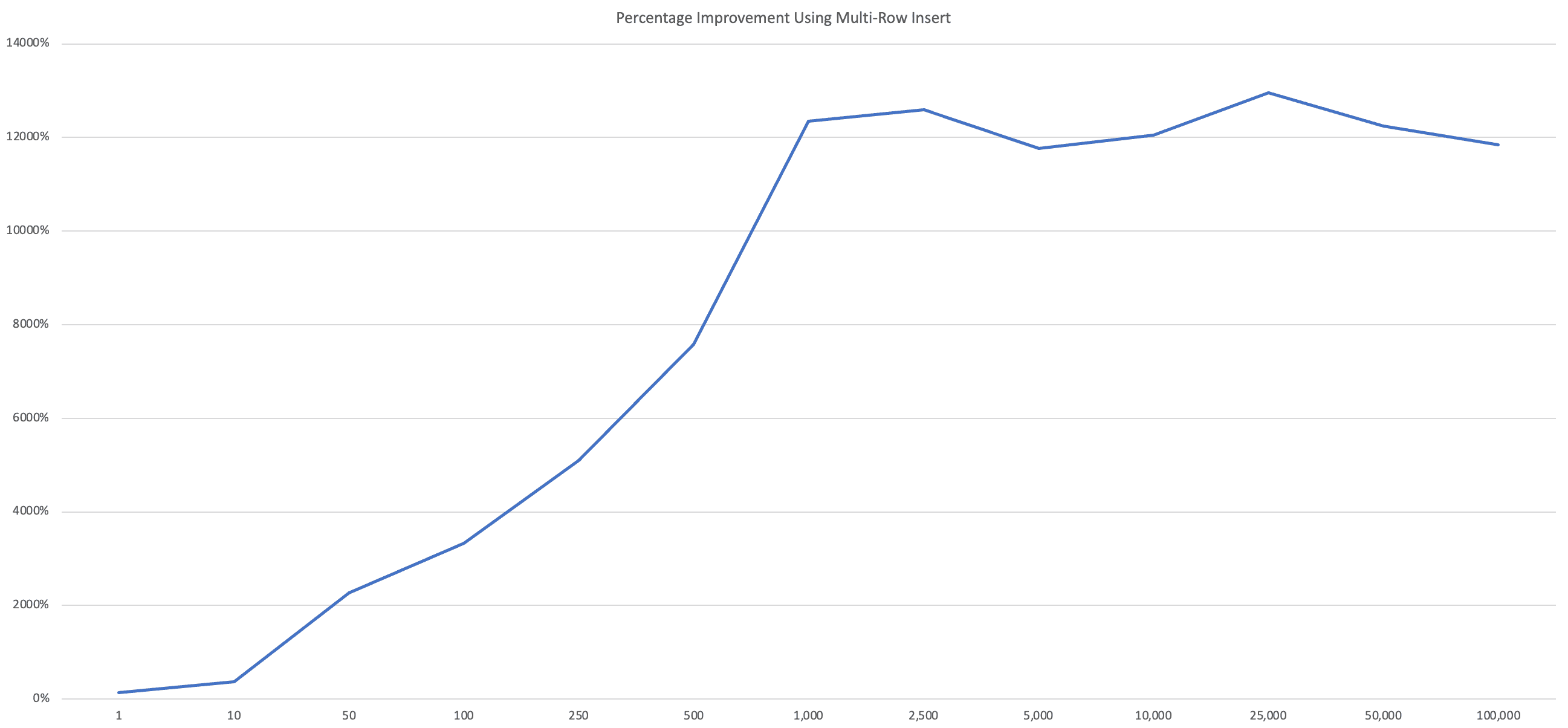
A quick glance will show just how much better the multi-row insert is; when inserting 1000 records (which isn't really that many) we can expect approximately a 12,000% improvement when using a multi-row insert.
Below is a chart of execution times for both methods. This chart is pretty funny and I almost wasn't going to include it in the post because the multi-row insert values are so low compared to the simple insert but I decided to include it to show just how extreme the benefit of a multi-row insert is.
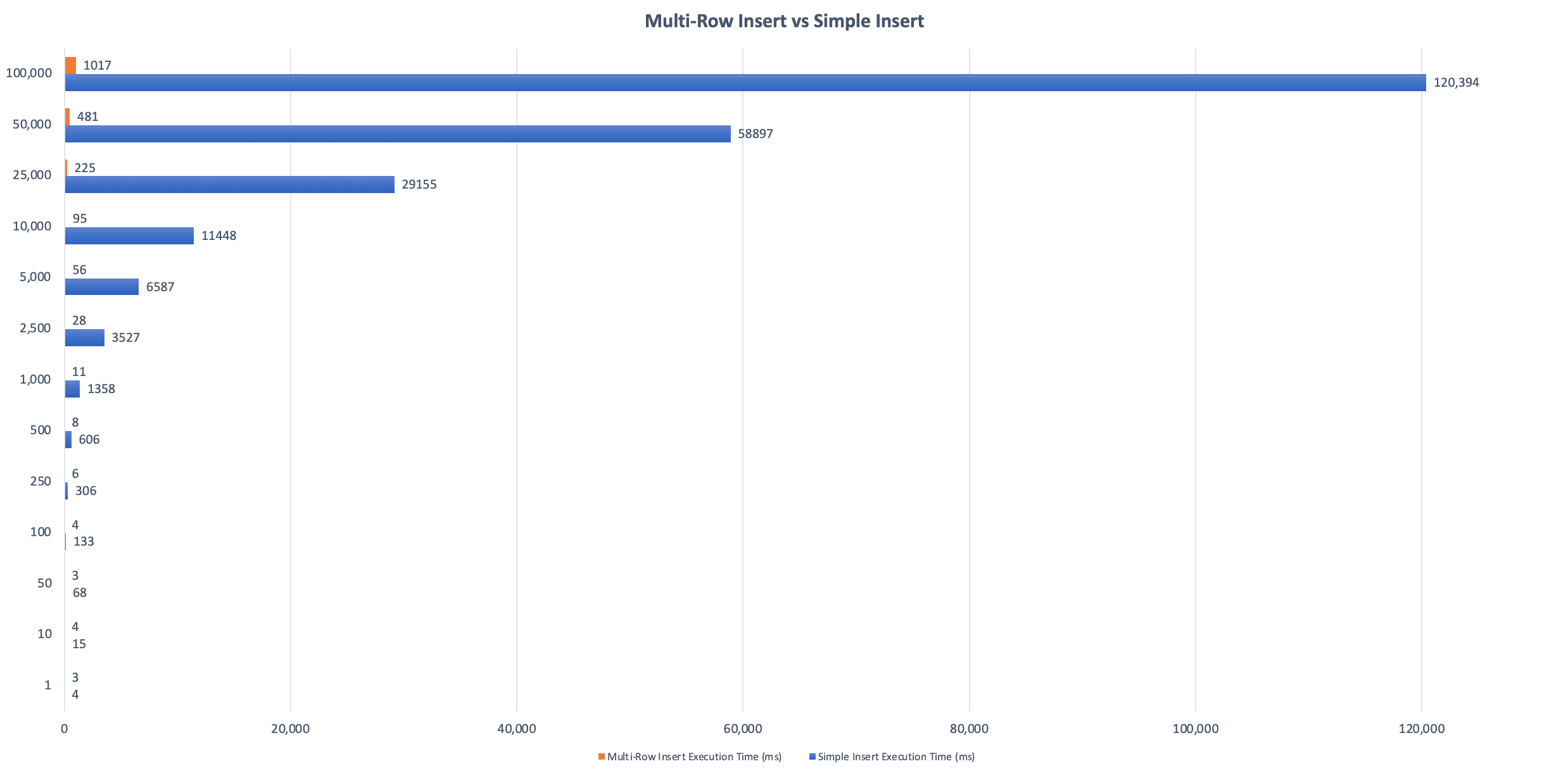
Also something to note from the results is that the percentage improvement stops increasing after 1000 records per batch. This happens because the tests used a batch size of 1000 rows; every 1000 results in another query so we stop seeing significant increases in the performance improvement at this batch size. If the batch size is increased to a value like 5000 then we would see increases up to 5000 rows and then the chart would level out again.
Conclusion
It's fairly obvious from the results that you should be making sure you are bulk inserting if you aren't already. Even when inserting 50 rows I was seeing a 2000% increase! Of course in my results the simple insert in this case was still pretty fast at 68ms so there may be little actual gain in using a multi-row insert in this case but we can see that as the number of rows increases that the benefit also significantly increases.
However, anecdotally, I have found that iteratively inserting a couple of hundred rows as separate statements tended to drastically increase the CPU utilization of the database, sometimes to over 90%. This could cause performance problems elsewhere and cause even simple queries to time out due to the increased load on the database. So bear in mind that using a bulk insert is not only fast but also reduces general load.
So in summary, I would like to conclude what we all already know: bulk inserting is good.